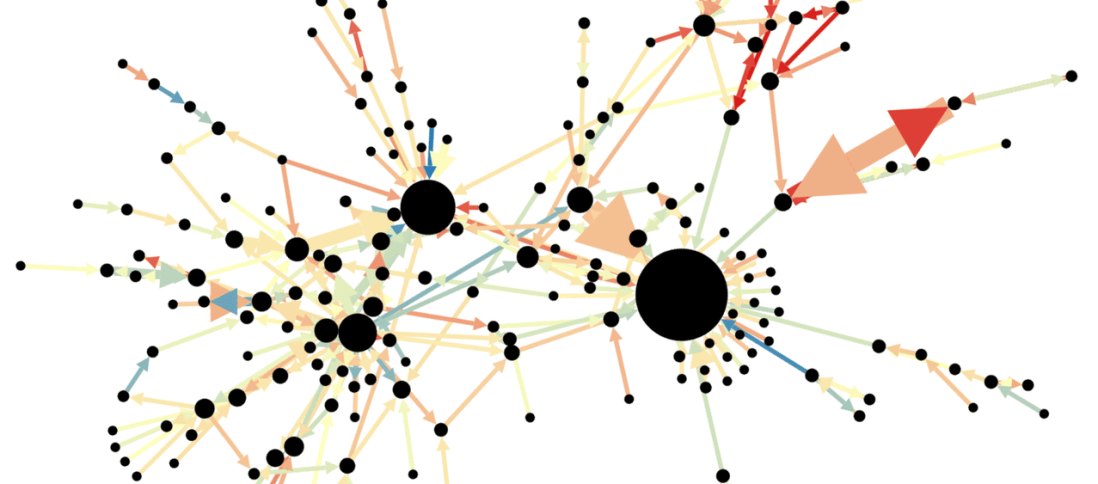
So far I've been looking at how researchers analyze social media networks, and perform tasks like opinion or sentiment analysis to understand how people feel and think about various subjects and entities. With this annotation we're looking at a thing called content marketing, where influential users of a social network are first identified, then used to spread messages to their network of influence. Even in a huge network, a little bit of leverage in the right places can move products, and perhaps elections.
Annotation – Content Marketing Through Data Mining on Facebook Social Network