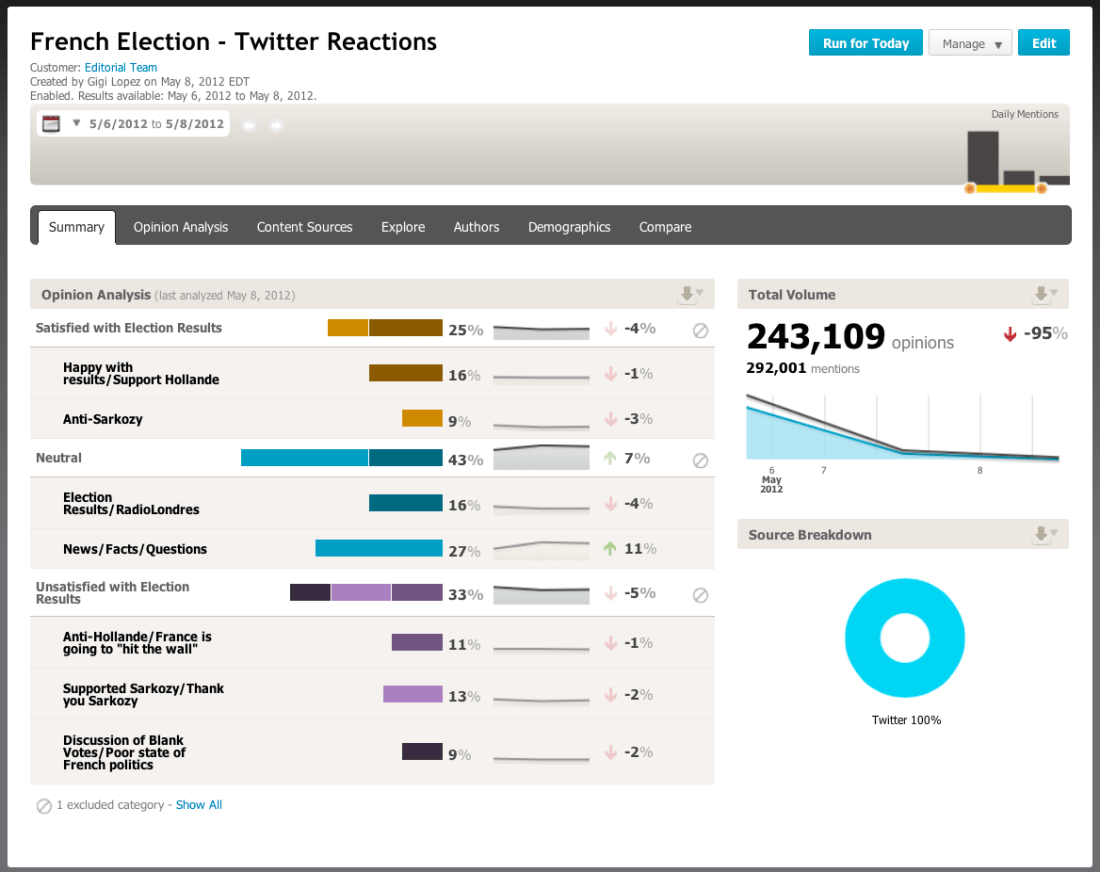
We've arrived at the inevitable point of imperfection. I started out looking for authoritative resources on how social media data is harvested, processed, and used in commercial and political communication campaigns, and I sure did find them. The problem is this realm is changing so fast, many of these sources are out of date. Regardless, this research project must come to an end on May 11th when I turn in my IS 452 final project. My proposed annotated bibliography has become a series of marginal blog posts. But the fight continues.
An Overabundance of Research, Data, and Tools